Welcome to the wonderful world of data audits. As anyone who has ever dealt with annoying managers and clueless users knows, the word "database" is thrown around to skirt responsibility and as a crutch. We all know managers who don't believe a report because they "know the numbers aren't right", and users who "don't know how the client's email got deleted". For us developers, audit data is a lifesaver. Why? Because data doesn't lie. It may not always tell us what we want to hear - it may tell us an application is broken or a user is doing something they shouldn't be - but that's not the data's fault.
So, how do we make data auditing dynamic, efficient and ruthlessly accurate? That's the subject for todays post. To accomplish this, we will use
Tables,
Triggers,
Functions and
Procedures.
As usual, all bold keywords, references and pertinent articles are linked to at the end of the post.
Let's start our scenario with a simple table called Orders, as represented by the following script:
In order to get audit data on each
INSERT and
UPDATE, we need to utilize triggers. However, to do this effectively we would need to handle each column and write data to an audit table. This may seem cumbersome, probably because it is. So, to make this scenario dynamic we are going to start with an additional table, as modeled below:
Each time we INSERT or UPDATE a record, the data will be added to this table. A trigger similar to the snippet below would be required:
As we can imagine, writing a trigger similar to this for each table, including each column would be a task and a half. So... why not have a procedure do it for us? This is taking the dynamic piece of the data audit model to the next level. But, before we write the procedure to do all of this for us, let's stop and think about the triggers.
Sure, writing them in the first place is a chore. But, what if we don't care about a column or two in our audits. Say for example we had 2 columns in our Orders table called Changed_At and Changed_By. These simply recorded the user and time stamp of the last change. We wouldn't need to audit these, since they are, in a way, an inline audit method. So, to make the column auditing dynamic, let's create 2 additional tables and a function.
The 2 tables are very simple and between them contain only 6 columns. They are modeled below:
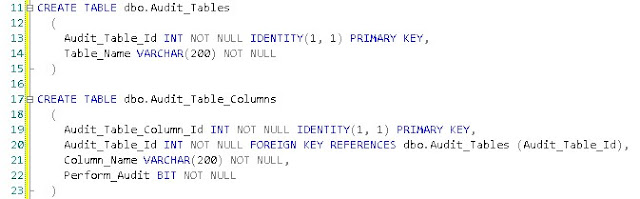.bmp)
The idea here is very simple, we can tell the trigger to audit or ignore any given column in a table we have. The creation and or updating of the trigger will be done inside the procedure we will write in a moment. Before that we will need a function. All this function does is return a table of all the columns we have decided to audit on a given table. The function could be written as follows:
This function is very simple, and joins the tables we just created on the
INFORMATION_SCHEMA. The result: a table of the columns that a) actually exist in the table and b) are set to be audited for the passed in table name.
Now, it's time to move on to the actual procedure that does the manual labor for us. Broken into logical pieces, the first bit is as follows:
The procedure takes only 3 (at most, and 1 at minimum) input parameters and outputs 2. The table name is self-explanatory, and the
@ForInsert and
@ForUpdate bits will allow us further dynamic-ness by letting us choose if we want to audit one type or another or both.
The first few lines set up our output values to their defaults and do some basic validation. After all, if we do not want to use insert nor update triggers, what is there to do? And if the table doesn't exist - if there is no valid
OBJECT_ID - then we can't rightly add triggers to it.
After that, some basic variables are declared that we will utilize in the following snippets.
This is the declaration of the try block that will allow us to catch fatal errors and report them to the user via the
@Success and
@Message outputs. The first order of business is to get the
primary key for the passed table. This example will only work if there is a single PK on the table; no more; no less. For other scenarios, the code would need to be modified slightly.
If we are going to use insert triggers, this block constructs
dynamic SQL and places it into the
@ColumnTriggerSection variable using a
WHILE loop. The loop is populated from the INFORMATION_SCHEMA and writes the trigger for all columns in the table. You may choose to exclude the PK field, and to do so would be as easy as adding an additional
WHERE clause to the insert.
The setting of the trigger section using dynamic SQL is quite easy, since we are essentially using the code from the trigger example towards the beginning and just adding it in a loop. The final section for the insert just adds the trigger declaration and body and, most importantly, determines if we need to
DROP/
CREATE or just a CREATE.
The code that follows, for the update trigger portion is virtually identical. The differences are in the dynamic SQL that we generate in the loop for each column and the creation of the trigger itself. These need to be slightly different, as the name cannot be duplicated, and on update, we are going to record the old value and the new value.
Now that we have all of our objects created: audit data table, audit customization tables, audit column function and our dynamic trigger creation procedure - let's test her out.
Let's first execute our procedure for the Orders table like so:
Next, let's add some data into the Orders table via an insert, then change some of it via an update. For example, we forget to add the customer's email address and sign them up for a subscription.
The results, when we query our Audit_Data table would be similar to this:
As we can see, our original insert created values in the New_Value column only, since there technically was no old data. However, when we updated, we can see new rows with a different timestamp for the 2 columns we updated.
Summary: we now can track every change on every row - transparently, dynamically and mercilessly.
Tables
Triggers
Functions
Procedures
INSERT Statement
UPDATE Statement
INFORMATION_SCHEMA
OBJECT_ID
Primary Key Constraints
Dynamic SQL
WHILE Loop
WHERE Clause
Drop Trigger
Create Trigger



.bmp)
.bmp)
.bmp)
.bmp)
.bmp)
.bmp)
.bmp)
+of+New+Picture+(9).bmp)
+of+New+Picture+(9).bmp)
.bmp)
.bmp)
.bmp)
.bmp)

.bmp)
.bmp)
.bmp)
.bmp)
.bmp)
.bmp)
.bmp)